Why does capital efficiency depend on simplifying Kubernetes?
Over the past two years, venture capital funding for AI startups has surged, bringing both extraordinary opportunities and harsh realities. Startups entering GenAI face intense execution pressure. The challenge isn’t just building a model — it’s doing so with capital discipline, speed, and reliability.
At the heart of modern AI infrastructure is Kubernetes. Its scalability, portability, and rich ecosystem make it the best platform for running diverse AI workloads — from model training on GPUs to large-scale inference. Kubernetes gives startups the flexibility to adapt quickly as their architecture evolves.
But that power comes with a cost. Managing Kubernetes at scale requires significant operational expertise. For resource-constrained startups, the overhead of provisioning nodes, applying patches, scaling clusters, and coordinating upgrades can consume precious runway — slowing down innovation and straining capital efficiency.
A recent MIT study found that 95% of generative AI projects are failing, primarily due to execution gaps, infrastructure complexity, and lack of capital discipline. For startups, this translates into lost time and funding due to infrastructure work instead of building differentiated AI products.
This article explores these challenges in depth and shows how solutions like Amazon EKS Auto Mode can help startups preserve Kubernetes’ strengths while automating lifecycle operations.
Scaling GenAI Startups Successfully: Key Infrastructure Considerations
While Kubernetes provides an ideal environment for AI workloads, its management complexity creates four critical challenges for startups:
Financial Strain and Hidden Costs
Hidden infrastructure costs plague early-stage startups through idle GPUs and manual scaling overhead. Repeated training jobs in AI development drain budgets faster than anticipated, especially for teams with limited scaling experience. Pre-revenue startups struggle as workload management consumes substantial resources, directly affecting investor discussions about burn rates.
Speed to Market Barriers
Operational demands, including setup, GPU scheduling, and system patches, can create significant delays. Each slowdown matters in the competitive AI landscape, where success hinges on rapid iteration and customer feedback. Infrastructure maintenance diverts crucial resources from core product development and feature innovation.
Talent Constraints
The scarcity of Kubernetes experts forces ML engineers to split their focus between model development and cluster management. This dual responsibility hampers productivity and creates an unsustainable cycle—competition with tech giants for specialized talent further strains startup resources.
Operational Risk
Enterprise clients demand unwavering reliability and compliance. System misconfigurations or driver mismatches can derail critical demonstrations. Startups face a difficult choice: overprovision and drain capital, or risk performance issues through under-provisioning. Both options threaten business reputation and stability.
The Path Forward
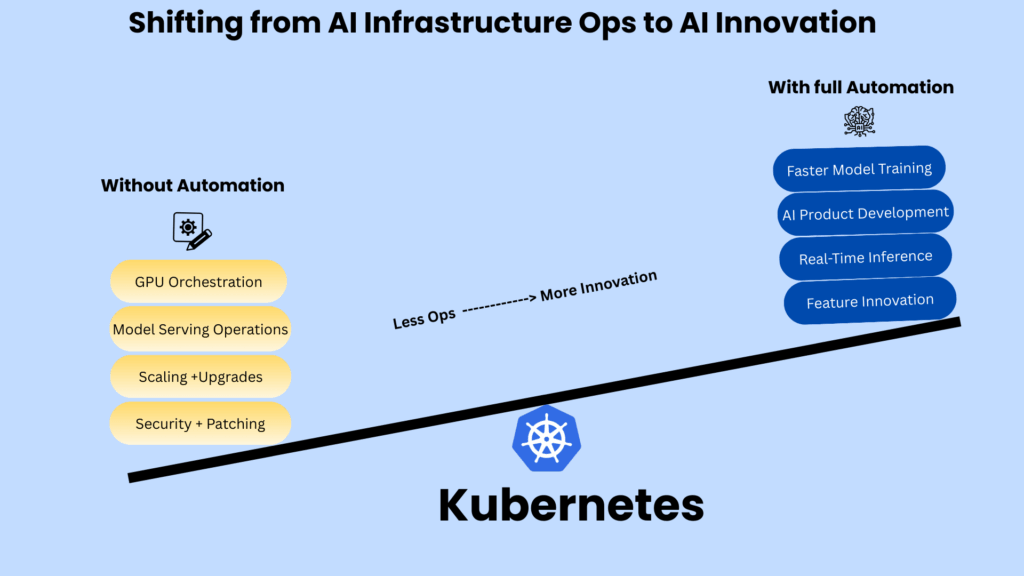
These interlinked challenges highlight the need for solutions that abstract Kubernetes complexity while maintaining its benefits. Forward-looking startups are turning to managed services like Amazon EKS Auto Mode, which preserve Kubernetes’ scalability and flexibility while reducing operational burden. The result: capital efficiency, faster innovation, and a better chance of success in the GenAI race.
Turning Pain Points into Advantages with Amazon EKS Auto Mode
For founders and CTOs, the challenge is maximizing innovation while minimizing infrastructure overhead. Amazon EKS Auto Mode addresses this by automating Kubernetes operations, transforming typical startup constraints into growth enablers.
Lower Infrastructure Costs: Amazon EKS Auto Mode streamlines infrastructure management with robust GPU support. Powered by Karpenter, it dynamically autoscales GPU-accelerated instances based on pod requirements. It automatically provisions appropriate instances that match your specific pod needs.
Operational Burden Reduced to Near-Zero: Pre-installed EKS-optimized AMIs and GPU components eliminate manual operations. The monitoring system detects GPU failures and repairs nodes automatically to maintain workload stability. EKS Auto Mode handles all node management, autoscaling, AMI updates, patching, and Kubernetes version upgrades.
Faster Time-to-Market with Fewer Distractions: Your engineers focus on shipping features and improving AI models instead of tuning infrastructure. Teams concentrate on deploying and scaling business-critical applications rather than configuring node components, managing security patches, or maintaining operational tools.
Enterprise-Grade Security Made Simple: EKS Auto Mode implements built-in safeguards, hardened operating systems, and managed security controls. Small teams achieve enterprise-grade reliability from day one. Bottlerocket secures containerized workloads, while AWS manages EC2 instances to ensure enterprise-grade security.
Alternative Opportunities for Start-up Efficiencies
Custom Silicon Solutions: With GPU shortages driving up infrastructure costs, startups are turning to cloud providers offering custom silicon alternatives. Amazon’s Inferentia and Trainium chips deliver cost-effective performance for both training and inference workloads, helping minimize raw cloud expenses.
Evolution of Infrastructure Needs: Early-stage startups with data science teams often start with Amazon SageMaker for rapid experimentation. As needs evolve, transitioning to Amazon EKS Auto Mode provides flexibility for custom workflows and broader tooling, while maintaining simplified infrastructure management.
Accelerating Innovation with EKS Auto Mode’s Automated Operations
For startups, Kubernetes is the growth engine — the most powerful foundation for scaling AI workloads. Its flexibility, portability, and ecosystem make it the platform of choice for training on GPUs, running inference at scale, and adapting to evolving architectures. But operating Kubernetes at scale creates overhead most early-stage teams can’t absorb.
While Kubernetes is essential for scaling AI workloads, its complexity often derails startups. Managed solutions like EKS Auto Mode let startups keep the benefits of Kubernetes without the operational burden, so they can focus on building their product and reaching the market faster.
For AI startups, the question becomes: what could teams accomplish when they can focus entirely on application development instead of managing Kubernetes infrastructure?
Note: This blog post, co-developed with AWS, is the second part of a 2-part series. The first installment covered challenges faced by enterprises in managing cloud workloads and how managed clusters help overcome these hurdles.